
The most important task when creating a machine learning (ML) application is to define the problem, i.e., what problem the application needs to solve and how to measure its success.
Machine learning engineers who work on creating the model must first understand the essence of the problem. Consequently, it’s necessary to have a person acting as an expert in a given field who understands the essence of the issue and how the model can help solve it. This person participates in the team’s work, takes care of the quality of the transferred knowledge, and answers questions that arise during the project.
Before starting any work on the model, it’s worth analyzing whether machine learning is the right tool to solve the problem. What should be considered at this point?
It’s impossible to train a good model without a lot of high-quality data.
What does a large quantity of data mean?
That depends both on the problem and the algorithm. There is no golden rule for specifying this amount. However, training an image classification model requires data in the tens of thousands, for example.
And what is high-quality data? High quality in this context means data with such a distribution that accurately and fully reflects the modeled phenomenon.
It’s not worth using ML for simple problems.
Some problems don’t require machine learning, which works well for finding complex and not always obvious dependencies. If there is a simpler, deterministic (rule-based) solution that produces results similar to the ML solution, it’s definitely better to stick with it.
The above issues should be discussed by the ML team and the specialist in the field at the planning and evaluation stage of the project.
87% of machine learning projects never go to production.
It’s worth reading the above sentence one more time because it shows quite well that ML projects are burdened with higher risk. This should be taken into account from the very beginning to minimize the risk of a potential project becoming part of that 87%.
Why does that happen?
First of all, you need to understand that the ML solution development process is very different from a typical software development process. It’s much more difficult to isolate project milestones and predict the time required for a specific task – this stems from the scientific-research nature of working with data. For people used to working with techniques such as Scrum, it may seem that the project is not moving forward. But remember that this is just a characteristic of this field.
But that’s not everything that’s special about this subset of AI development. Another characteristic of ML (resulting, again, from its exploratory nature) is that it’s impossible to predict how well the model can be trained. After understanding the customer’s expectations, the problem, and the data, you can take them as an indication that the results of the work on the model will be satisfactory. But you can never know for sure, as there are simply too many factors influencing it. Before starting any work, it’s necessary to establish the definition of done (Dod) that, with the agreement of both parties, determines the minimum expectations regarding the effectiveness of the model resulting from the work of the ML team.
We expect the potential client to be aware of and understand the above issues.
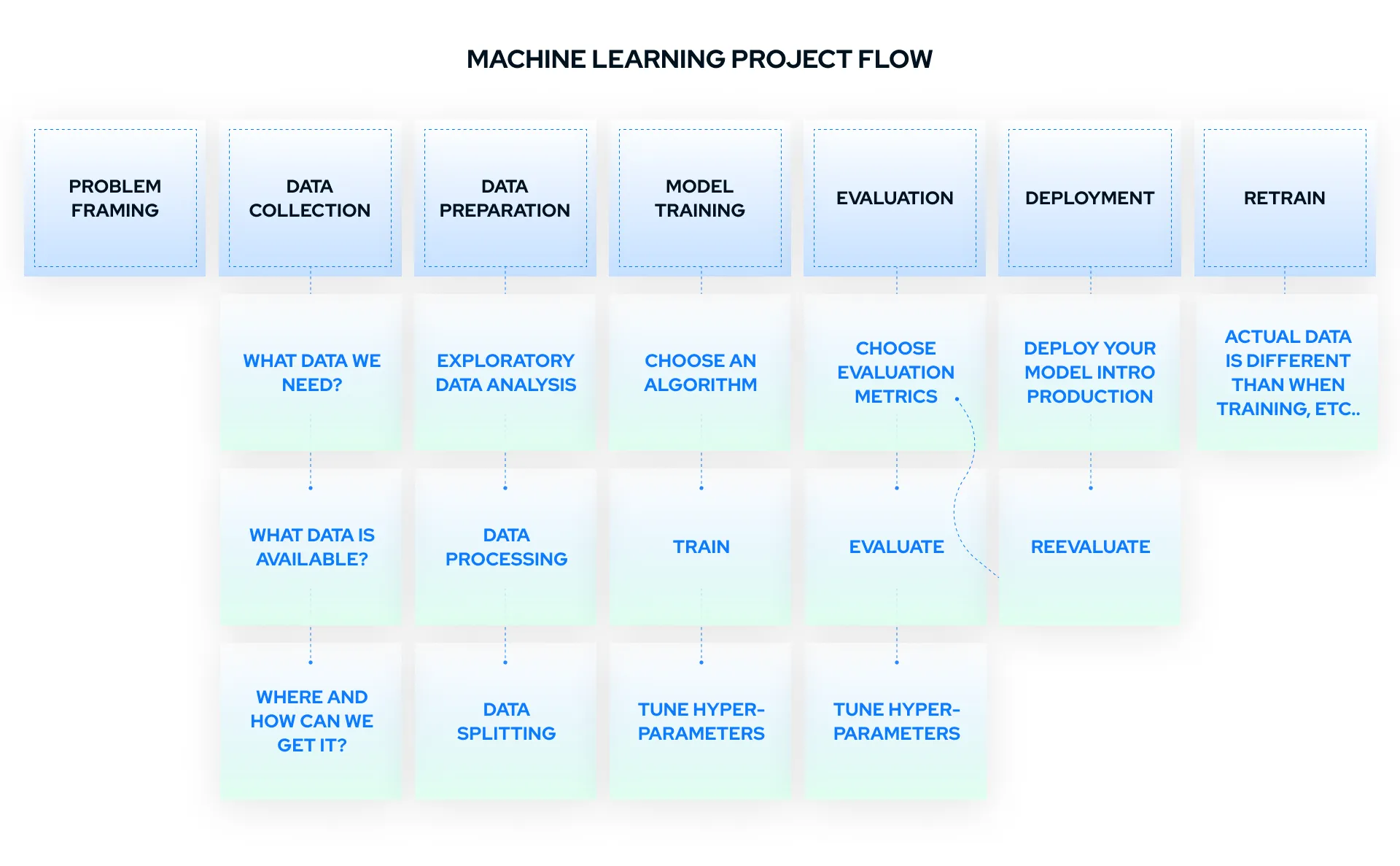
What you need and how to prepare it depends on the problem you’re trying to solve. The best solution is to present the problem and the data and – depending on the degree of confidentiality – provide a representative sample of the data to the ML team for initial evaluation and analysis.
It is also a good idea for the client to organize workshops introducing them to the subject of the project and, if possible (if they exist), the solutions already tried by the client. Such workshops also allow ML team members to ask questions and thoroughly understand the problem, which is an essential part of working on any ML solution.
The basic condition for successful cooperation is understanding the characteristics of machine learning projects described above. Before the project begins, it is a good idea to organize a meeting between the ML team leader and the product owner (PO), where the expectations and past experiences of both parties will be discussed. The solution developed in this way will provide the most optimal solution in terms of efficiency and satisfaction for both parties.
After the model has been developed and trained (in line with the provisions of the Dod), the team prepares a presentation of the model’s operation, its results, and potential further work on the model. Perhaps the operation of the model, although it meets the established criteria, can be improved somehow? Or maybe machine learning can help solve another problem at the client’s company?
The result of the team’s work will be a machine learning model wrapped in a separate application or implemented into the existing internal customer system and documentation. Depending on the characteristics of the domain/data, it may be necessary to train the model periodically to ensure the reliability of the results it generates. In this case, the team organizes workshops for people working with the application/system.
