
With increased data processing capabilities, organizations are more and more interested in analyzing internal and external data to find previously hidden links that can improve operational efficiency, sales, and competitiveness.
From startups to enterprises, companies are today using advanced statistical techniques to analyze large amounts of data to uncover meaningful business relationships, enabling them to increase profitability and promote business growth. Such analytics include predictive modeling, simulation, optimization, scenario planning, and data mining – with some approaches using machine learning (ML).
Machine learning is significant because it helps create new products and provides businesses with a picture of trends across consumer behavior and operational patterns. A significant portion of the operations of many of today’s top businesses, like Meta, Google, and Uber, revolves around machine learning. For many organizations, machine learning insights have become a key competitive differentiator.
What exactly is machine learning, and how does it work? Keep reading to get an overview of machine learning essentials for 2023.
Machine learning (ML) is a branch of artificial intelligence (AI) that allows machines to learn “without explicitly being programmed”. ML applications can learn, grow, expand, and adapt autonomously using fresh data.
Machine learning uses algorithms to find patterns in massive data sets and learn iteratively. During the learning process, ML models improve when exposed to carefully curated data sets.
With the rise of technologies and methods like big data, the Internet of Things (IoT), and cloud computing, machine learning has become an important way to solve problems in many fields, such as:
– Computational finance (credit scoring, algorithmic trading),
– Computer vision (facial recognition, motion tracking, object detection),
– Bioinformatics (DNA sequencing, AI used in drug discovery),
– Automotive and manufacturing (predictive maintenance),
– Natural Language Processing (voice recognition, virtual assistants, chatbots like ChatGPT).

It all started with neuron models introduced by Donald Hebb in The Organization of Behavior, published in 1949. The Hebbian Theory, that originates from that publication, is often summed up with the words “Cells that fire together wire together”, meaning that if two neurons are active at the same time, their connections strengthen.
Next, in the 1950s, IBM’s Arthur Samuel created a checkers software that was capable of playing with world champions. The minimax algorithm decided the program’s next move. Samuel created several techniques to improve his program. In rote learning, Samuel’s algorithm associated reward function values with all positions observed. Arthur Samuel actually coined the term “machine learning” in 1952.
A few years later, Frank Rosenblatt at Cornell Aeronautical Laboratory merged Donald Hebb’s neuron model with Arthur Samuel’s machine learning research to build the perceptron in 1957. Perceptrons were originally machines, not programs. The Mark 1 perceptron was an image recognition computer that used IBM 704 software.
However, the “neuro-computer” didn’t meet the expectations. The project’s development stalled because it couldn’t distinguish numerous visual patterns, including faces.
Pattern recognition began with the nearest neighbor algorithm developed in 1967. This method was one of the first ones to solve the traveling salesman problem of determining the most effective path – an optimization issue aiming at finding an optimal way connecting all the towns the salesman is supposed to visit.
Multilayers changed neural network research in the 1960s. Two or more perceptron layers provide much greater computing capabilities than a single layer. With the introduction of multiple layers, other neural network architectures emerged – for example, the multiple-layer feedforward neural networks.
The backpropagation algorithm was developed in the 1970s. It measures the difference between a network’s output and the real, expected output, which can then be used to alter the model’s weights to (hopefully) make better predictions the next time.
Thanks to multiple layers of artificial neural networks (ANNs) can handle more complex tasks than perceptrons and identify patterns too complicated for a human to recognize and analyze.
There were two major AI winters in 1974–1980 and 1987–1993. AI winter is a period when funding and interest in AI research are low, the name alluding to the term “nuclear winter.” Hype cycles were followed by disappointment and criticism, funding cuts, and then renewed enthusiasm years and decades later.
Jürgen Schmidhuber and Sepp Hochreiter’s 1997 neural network model, long short-term memory (LSTM), is still one of the most widely used algorithms in voice recognition problems today.
Speech requires the memory of thousands of discrete steps, which LSTM can learn. Long short-term memory outperformed voice recognition systems in 2007.
Since the development of LSTM, numerous voice recognition systems have been built, including but not limited to:
– Google Speech Recognition: One of the most widely used speech recognition systems, Google Speech Recognition is used in Google Assistant, Google Translate, and Google Voice Search. It uses deep neural networks to recognize speech in multiple languages.
– Amazon Alexa: Alexa is an intelligent personal assistant developed by Amazon that uses automatic speech recognition (ASR) to understand and respond to voice commands. Alexa combines deep learning algorithms and natural language processing (NLP) to understand and interpret spoken language.
– Apple Siri: Siri is Apple’s virtual assistant that uses voice recognition to understand and execute user commands. Siri uses machine learning algorithms to recognize speech and natural language processing techniques to understand user intent.
– Microsoft Cortana: Cortana is Microsoft’s virtual assistant that uses speech recognition and natural language processing to interact with users. Cortana uses deep learning algorithms to recognize speech and perform tasks based on user input.
– IBM Watson: IBM Watson is a powerful cognitive computing system that uses speech recognition, natural language processing, and machine learning to understand and analyze unstructured data, including speech. IBM Watson is used in a variety of applications, including healthcare, finance, and customer service.
These are just a few examples of the many voice recognition systems available today, each with its own unique features and capabilities.
The LSTM model and its performance in speech recognition is well-documented in various sources. This article published in a collection on neural computation supports this claim – and it dates back to 1997! More recent approaches are presented in studies from Graves and Schmidhuber, as well as Graves, Mohamed, and Hinton (that’s right, the same George Hinton who has recently spoken against the current AI research). These papers demonstrate the effectiveness of LSTM networks in speech recognition and their widespread use in modern systems.
The 2006 National Institute of Standards and Technology Face Recognition Grand Challenge assessed popular facial recognition algorithms like Iris, 3D face scans, and high-resolution facial photos.
The new algorithms were ten times more accurate than the 2002 facial recognition algorithms and 100 times more accurate than the 1995 methods. Some computers recognize faces better than humans and even distinguish identical twins.
Google’s X Lab created an ML system that searched for cat videos in 2012. DeepFace was developed by Facebook in 2014 to recognize and verify people in photos.
Machine learning is behind some of the biggest technological advances. It’s used for anything from self-driving cars to exoplanet identification, benefiting from advances in various programming languages.
Machine learning flourished thanks to the development of specialized algorithms, data attainability and training capabilities, as well as access to high-performance computing power from top cloud providers.
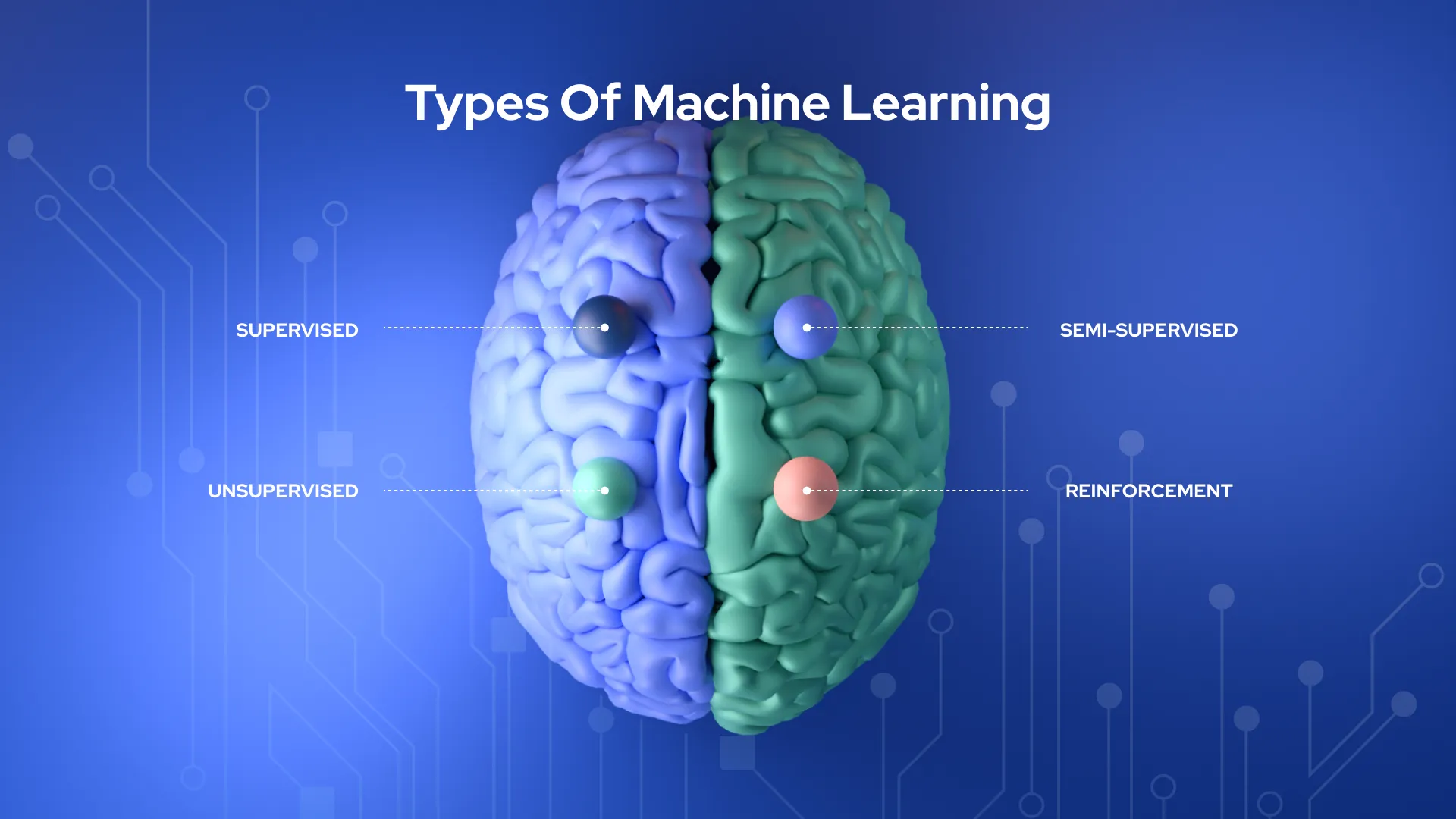
Machine learning algorithms can be trained in a variety of ways, each with unique advantages and drawbacks. Based on these methods and ways of learning, machine learning can be broken up into four main groups:
In this variant, computers are trained on labeled datasets. Certain input and output parameters are already mapped according to the labeled dataset. As a result, the machine is taught using the input and output.
Consider the following dataset: parrot and pigeon photos. First, the system is trained to recognize the images that include the color, eyes, form, and size of the parrot and pigeon. Following training, an image of a parrot is presented as input, and the machine learning model should be able to correctly classify it as a parrot.
The primary goal of this technique is to translate the input variable to the output variable.
There are two major categories of supervised machine learning:
Classification algorithms – they solve classification issues using categorical output variables, such as yes or no, true or false, male or female, and so on. This category’s real-world applications include spam detection and email filtering.
Some well-known ways to classify things are Random Forest Algorithm, Classification Decision Tree Algorithm, Logistic Regression Algorithm, and Support Vector Machine Algorithm.
Regression algorithms – they deal with regression situations in which the input and output variables have a linear relationship. These are well-known predictors of continuous output variables. Weather forecasting, market trend research, and other applications are examples.
Popular regression techniques include the Simple Linear Regression Algorithm, Multivariate Regression Algorithm, Regression Decision Tree Algorithm, and Lasso Regression.
This learning strategy doesn’t require supervision. The machine is trained on an unlabeled dataset and can predict the output without human intervention. An unsupervised learning algorithm tries to group the unsorted dataset based on similarities, differences, and patterns in the input.
Here’s an example input dataset: photos of a container filled with bananas. The photos in this case are unknown to the machine learning model. As we feed the dataset into the ML model, the model’s objective is to recognize and categorize the patterns of objects visible in the input photographs, such as color, form, or differences. Following classification, the machine predicts the output while being tested with a test dataset.
Unsupervised machine learning is divided into several types:
Dimensionality reduction refers to the process of reducing the number of input characteristics in a dataset. Anomaly detection is about recognizing examples that deviate significantly from the norm, whereas clustering entails combining related occurrences into clusters.
Semi-supervised machine learning combines aspects of both supervised and unsupervised machine learning. It trains algorithms using a combination of labeled and unlabeled datasets, thereby solving the disadvantages of supervised and unsupervised learning.
Take the following example of a university student. In university, supervised learning is basically the student studying an idea under the instructor’s supervision. Unsupervised learning happens when the student learns the same material without the instructor’s guidance.
And then there’s another type of learning where the student reviews the concept on their own after learning it under the supervision of an instructor. This represents the semi-supervised method of learning.
Reinforcement learning is a process that depends on feedback. The AI component uses the hit-and-trial approach to autonomously assess its surroundings, take action, learn from experiences, and improve performance. The component is awarded for each correct action and punished for an incorrect one. As a result, it seeks to maximize rewards by completing positive activities.
Unlike supervised learning, reinforcement learning doesn’t use labeled data, and learning happens only through experiences. Reinforcement learning is used in a variety of domains, including game theory, information theory, and multi-agent systems.
Reinforcement learning uses the following methods or algorithms:
Positive reinforcement learning – adding a reinforcing stimulus after a specific behavior of the agent increases the likelihood that the behavior will occur again in the future, for example, by adding a reward after a behavior.
Negative reinforcement learning – the process of improving a certain habit to avoid a bad result.
Clustering is another type of unsupervised machine learning. This method involves grouping similar data points or occurrences based on their characteristics without any prior knowledge of their labels or categories.
Engineers use this approach to identify inherent structures or patterns in the data that may not be immediately apparent. Clustering can come in handyl in various applications, such as customer segmentation, image recognition, and natural language processing.
Clustering algorithms use multiple techniques to measure the similarity or dissimilarity between data points and then group them into clusters accordingly. Some examples of popular clustering algorithms include k-means, hierarchical, and density-based clustering.
Natural language processing (NLP) is a discipline of computer science, linguistics and artificial intelligence (AI) that aims to make computers interpret text and speech like humans.
Computational linguistics—rule-based language modeling—is used in NLP. These technologies let computers “understand” text or audio data and the speaker’s or writer’s purpose and mood.
NLP powers computer programs that interpret text, reply to spoken requests, and summarize vast amounts of text quickly—even in real time. Digital assistants, speech-to-text dictation software, customer care chatbots, and other consumer products use NLP. NLP is being used more and more in enterprise solutions to improve business operations, boost employee productivity, and simplify mission-critical procedures.
Software that properly interprets text or speech input is difficult to create because human language is full of ambiguity. Homonyms, homophones, sarcasm, idioms, metaphors, grammar and usage exceptions, and variations in sentence structure—these are just a few of the irregularities of human language that take years to learn. Still, we see AI solutions making attempts even at writing poetry.
NLP engineers are tasked with teaching natural language-driven applications to recognize and understand accurately from the start if they are to be useful. For example, our ML team developed an AI chatbot that can act as an online customer support service across different sectors, from e-commerce to legal and energy companies.
Common NLP tasks include:
– Voice recognition (speech-to-text)—accurately converts voice input into text. Any software that responds to voice commands or inquiries needs speech recognition.
– Text-to-speech
– Machine translation
– Question answering
– Grammatical tagging—determines a word’s part of speech based on its use and context.
– Co-reference resolution—determines which words refer to the same entity in a text.
– Sentiment analysis—detects emotions, sarcasm, bewilderment, and suspicion from the text.
Deep learning algorithms use neural networks that must have more than three node layers or depth. An input, a weight, a bias or threshold, and an output are the four fundamental parts of a neural network. Deep neural networks give excellent results for unstructured data such as images or videos.
However, they require large data sets, operating with many more parameters, and performing much longer training that, in turn, calls for massive and expensive computing power.
Quality data is a key requirement for any machine learning project. It helps ML algorithmsimprove over time.
A machine learning dataset is composed of data rows representing one instance of a modeling phenomenon (for example, observation). A dataset is a group of all recorded observations.
Machine learning datasets are usually split into three parts: the training set, the validation set, and the test set. The training set is used explicitly for training a model, the validation dataset is used to monitor the learning process, and the test dataset is used to verify the final model on data it has never seen before, which tells us how the model would do on real-world data.
Machine learning models use three main types of data: numerical, categorical, and time series.
Here are the five most popular sources of machine learning datasets:
Google Dataset Search Engine was released in September 2018. It includes datasets on global temperatures, housing market statistics, and more. Each dataset includes a description, release date, and data source link.
Microsoft Research Open Data offers free selected datasets. To get reliable machine learning data, engineers can download research datasets or copy them to a cloud-based Data Science Virtual Machine.
AWS is one of the major on-demand cloud computing platforms. AWS resources offer many datasets due to Amazon’s massive data storage. The AWS Registry of Open Datacontains these datasets. Search, dataset descriptions, and usage examples make finding datasets easy.
UCI’s Machine Learning Repository database offers a lot of material to the public. This database contains almost 500 datasets, domain theories, and data generators. UCI also separates datasets by machine learning issue type, making searching easier.
The US government has made various datasets available. These datasets may be utilized for study, data visualization, web/mobile app development, and more. Data.gov houses US government data on education, the environment, agriculture, and public safety. Most nations have comparable databases.

Data science and machine learning careers have grown rapidly in recent years. In particular, machine learning is a thriving and rapidly developing discipline that has enormous prospects for growth.
The most lucrative industries of today, such as big data, predictive analytics, data mining, and computational statistics, all depend heavily on machine learning.
Machine learning is a fulfilling job option if you have knowledge of data, automation, and algorithms. To enter this field, you need strong research abilities, a fundamental knowledge of statistics, and a working knowledge of computer languages. People with a variety of diverse backgrounds, skills, and experiences can design their own ML learning journey.
Supervised ML includes regression. This method anticipates or explains a numerical value based on preceding data, such as estimating a property’s price based on similar properties’ prices.
Regression methods range from simple (linear regression) to complicated (like regularized linear regression, polynomial regression, decision trees regression, random forest regressions, and neural nets, among others). Start with simple linear regression, master it, and then continue.
Classification methods predict class values. Classification begins with logistic regression, the simplest classification model. There are also non-linear classifiers like Decision Trees, Random Forests, Support Vector Machines, and Neural Nets.
Clustering algorithms group related observations and are used in unsupervised ML. Clustering algorithms specify output instead of using output information for training.
These combine numerous predictive models (supervised ML) to improve prediction quality. For instance, the Random Forest technique mixes several Decision Trees trained with various data samples. Ensemble approaches lower the volatility and bias of a machine learning model.
Machine learning is applied in a wide variety of applications. The recommendation engine that runs Facebook’s news feed is perhaps one of the most well-known instances of machine learning in operation.
Facebook uses ML to customize how each member’s feed is presented. If a member often pauses to read the postings of a certain group, the recommendation engine will begin to show more of that group’s activity higher in the feed.
The engine is working behind the scenes to reinforce recognized trends in the members’ online activity. If the member’s reading habits change and they fail to read postings from that group in the future weeks, the news feed will be adjusted appropriately.
Aside from recommendation engines, machine learning may also be used for the following:
Customer relationship management — CRM software may evaluate emails using machine learning models and push sales team members to reply to the most essential communications first. More sophisticated programs can even suggest potentially useful answers.
Business Intelligence — BI and analytics software use machine learning to detect potentially valuable data points, patterns of data points, and anomalies.
Information systems for human resources — ML models may be used by HR systems to filter through applications and select the best applicants for an available post.
Autonomous vehicles — ML algorithms can even enable a semi-autonomous automobile to distinguish a partially visible item and inform the driver.
Virtual assistants — smart assistants often blend supervised and unsupervised machine learning models to analyze spoken speech and provide context.
With machine learning platforms, users can design, implement, and improve ML algorithms. These platforms automate data pipelines, processing, and optimization.
Machine learning platforms transform data into insights, drive business decisions, and improve goods and services as firms collect more data.
Such platforms open the door to shared insights as users may exchange data, models, and associated information through collaborative tools. They also offer optimized experimentation with data visualization, augmentation, and preparation tools.
Some ML platforms have drag-and-drop capabilities, and prebuilt algorithms are making AI solution development easier for data scientists. Non-technical employees may learn about machine learning models, data, and business impacts on some platforms.
Examples of ML platforms include IBM Watson Studio, Snowflake, Databricks, H2O, Dataiku, and Lakehouse Platform. The three major cloud service providers offer ML platforms as well – AWS SageMaker, Google AutoML and Vertex AI, and Azure Machine Learning solutions.
ML offers a lot of value to businesses and consumers, powering the most commonly used products and services. Machine learning algorithms help service companies detect clients who may leave. If you stopped using a credit card and received an email offering a reduced APR, your credit card company may be using machine learning to retain customers.
Sentiment analysis, often known as “opinion mining” or “emotion AI”, analyzes social media postings using natural language processing and machine learning. This study might reveal customer sentiment regarding a brand or product.
Naturally, ML is also indispensable for accelerating decision-making processes. This benefit applies to industries ranging from retail and logistics to healthcare and government.
Companies are putting machine learning into their models because it has made large-scale operations possible and opened up new business opportunities. However, organizations face a number of challenges.
AI and ML’s biggest issue at scale is that ML computational power allocation takes time and distracts from data research. Data science teams must also manage DL algorithms. Data versioning, model maintenance, software implementation, and open-source frameworks are many other challenging tasks that need to be taken care of for ML to work.
The industry is based on three major workflows that are sometimes difficult to combine. DevOps prioritizes resource management, infrastructure, and output visualization. Here, technical debt delays and costs manufacturing. Data science involves data gathering, processing, and model analysis. Another important workflow is MLOps, a set of practices for deploying and maintaining machine learning models in production reliably and efficiently.
Changes in the field have a huge effect on how enterprise ML applications are used. OpenAI’s buzz-worthy generative DL model called ChatGPT is one of them. The viral AI-powered chatbot writes essays, emails, poetry, and code. OpenAI plans to release ChatGPT Professional, the monetized version that will have no “blackout” windows, no throttling, and “at least 2x the standard daily limit” of messages, according to the source.
Machine learning algorithms may be employed more successfully when new technologies emerge. The future of machine learning clearly shows the rising applicability of machine learning across numerous industrial verticals. The technology will present many opportunities for enterprises.
Make sure your company is prepared to capitalize on what is coming and get a high ROI from all the data you’ve amassed over the years.
Our team of ML experts is here to help you figure out how to use ML in your business and find the right solution to speed up your growth.
